Synthetic Data Generation
Synthetic Data Generation using NVIDIA-Omniverse Replicator
Synthetic data generation in NVIDIA Omniverse is essential for creating realistic virtual environments, training AI models, augmenting datasets, addressing privacy concerns, and enabling rigorous testing and validation. It enhances the capabilities and reliability of AI systems developed within the Omniverse ecosystem.
NVIDIA Omniverse™ Replicator is an extensible set of APIs that enable developers to generate physically accurate synthetic data to accelerate the training of computer vision.
This blog will outline the installation and utilization steps for the replicator tool.
- Open the Omniverse launcher. The following screen will appear.
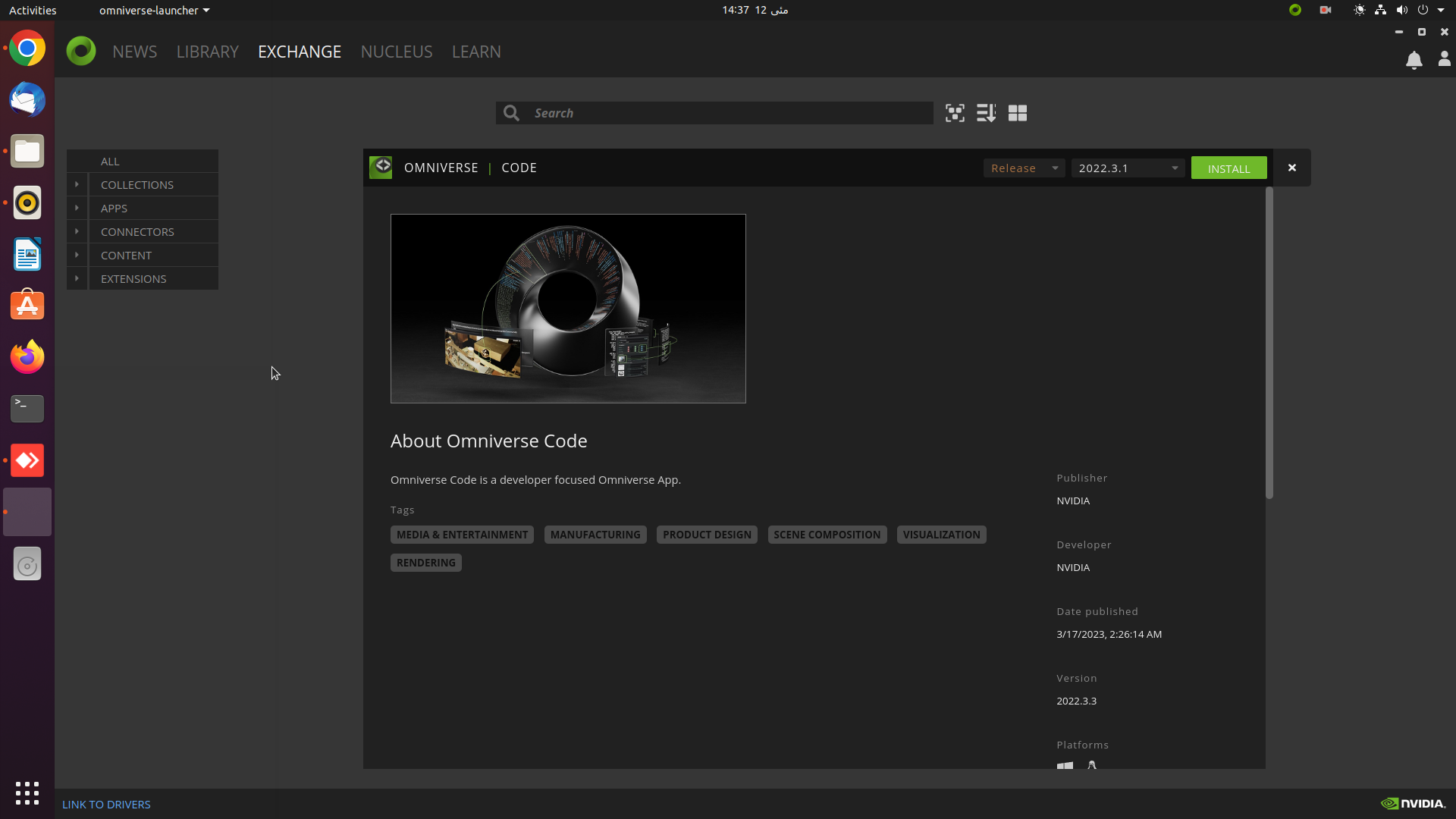
2. To install the Omniverse code app, go to the Exchange tab and click on the green button located in the top right corner.
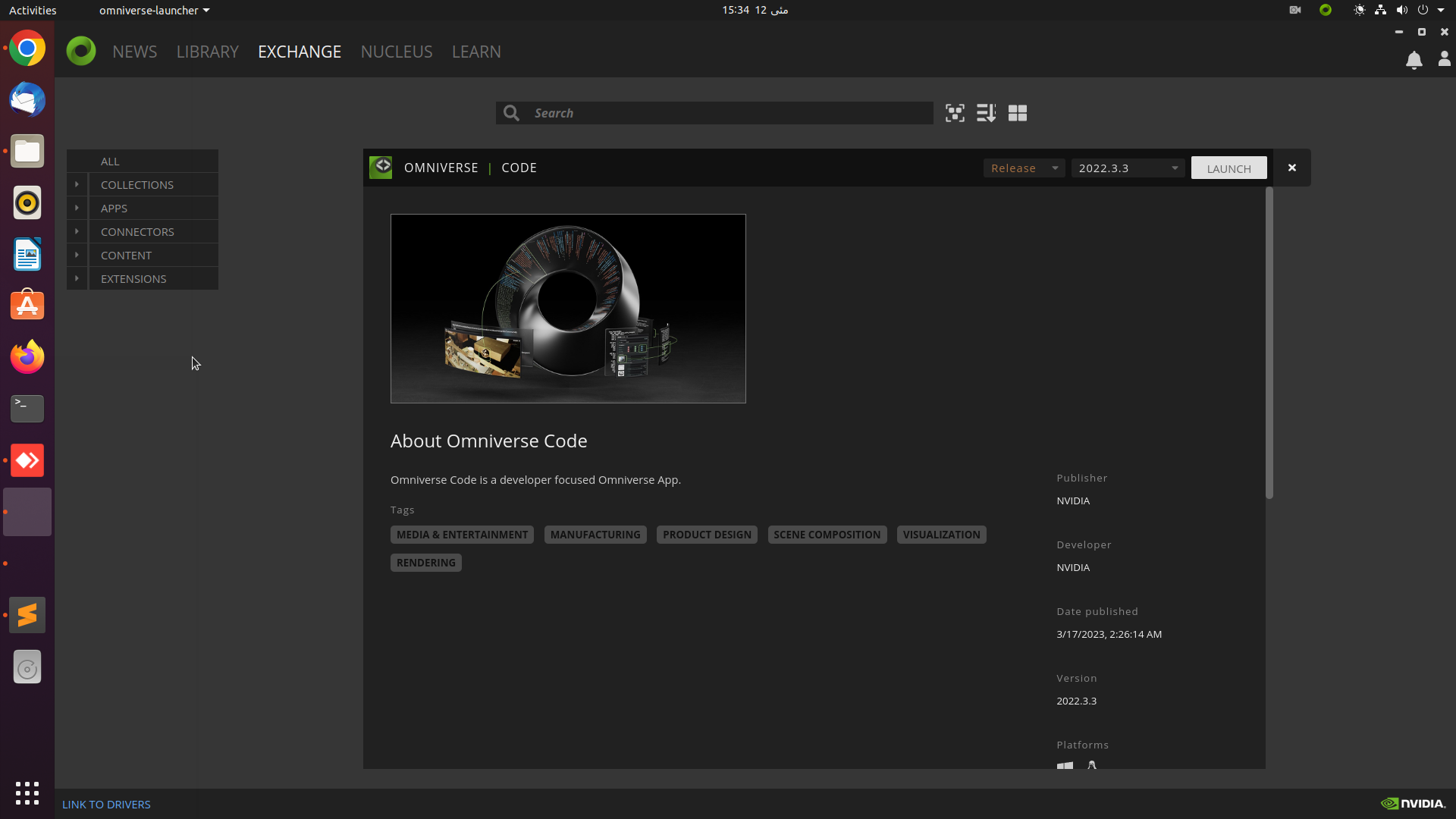
3. After installing the code app, the next step is to launch it by clicking the ‘LAUNCH’ button.
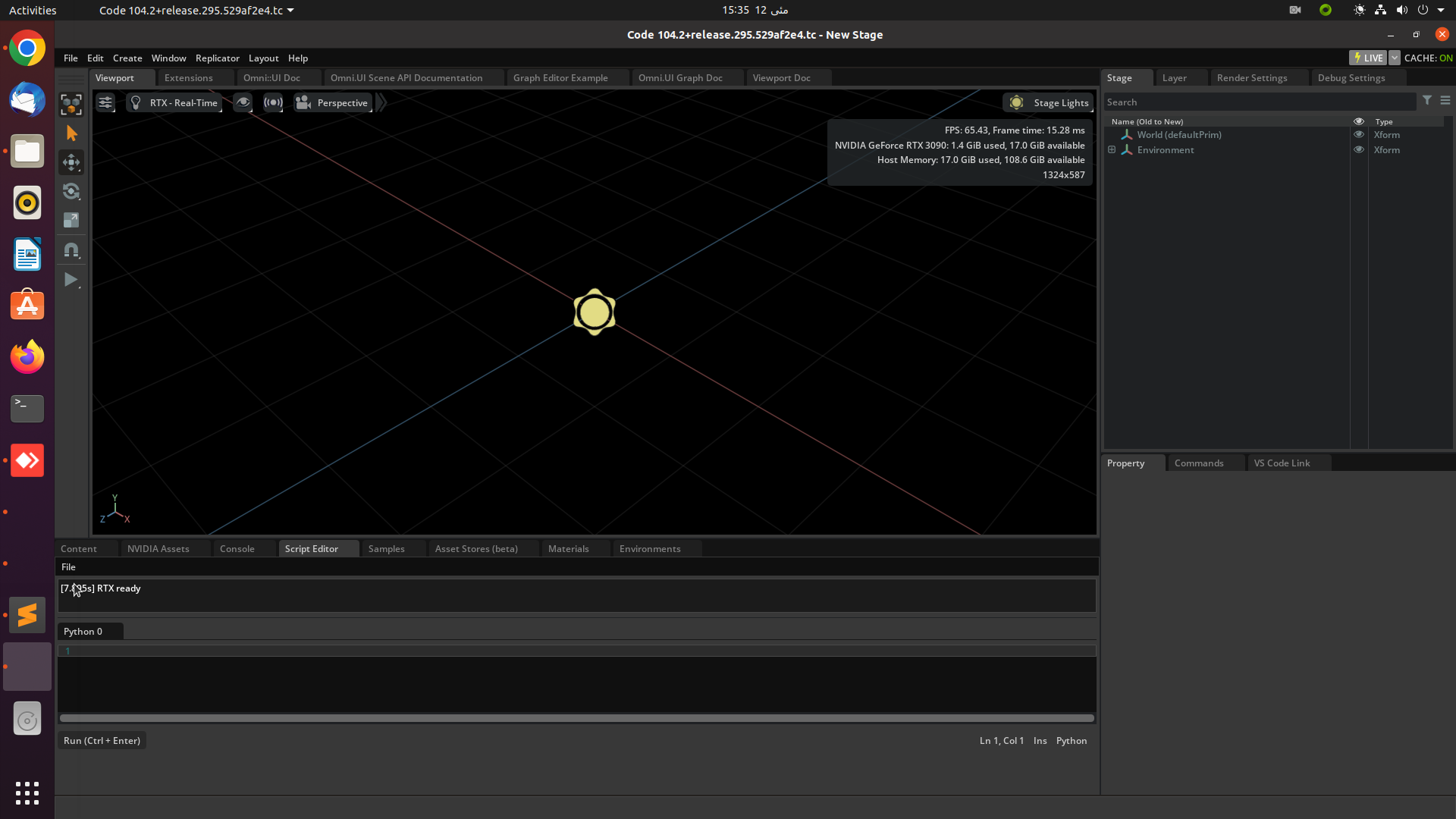
4. Now, select the ‘script editor’ tab to write a Python script.
5. The next step is to write the script in Python.
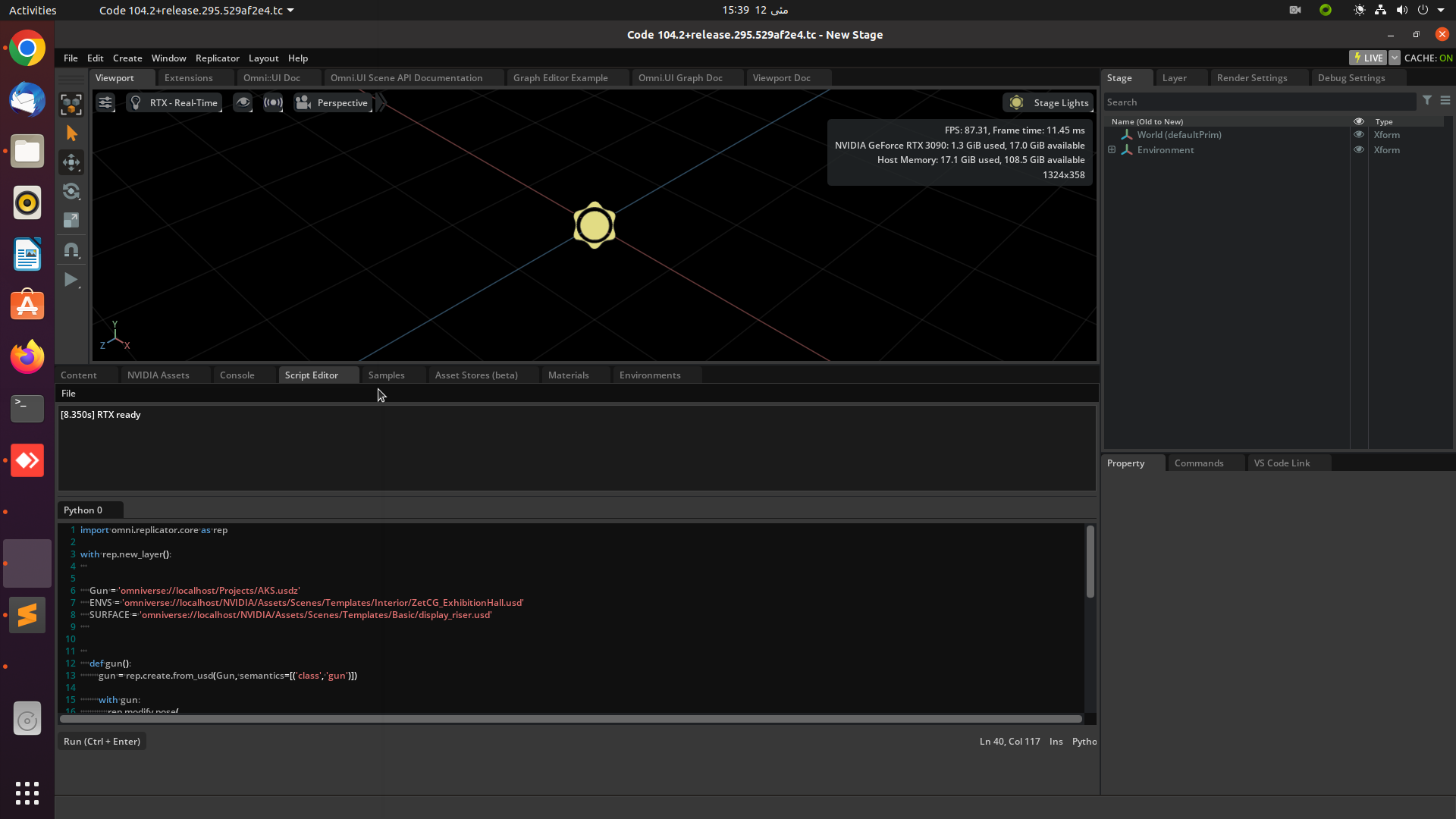
6. Now, hit ‘Replicator’ in the top left corner to start synthetic data generation or press Ctrl+Enter.
7. Synthetic Data Generation Python Code
Code: The first step is to import the library with the following Python code.

Initiating asset path. Here we want to generate gun dat. “Gun” is a gun asset, “ENVS” is the background environment, and “SURFACE” is a plane on which we can randomize the target object.

Write the function to attach the class with the target object. “Position” is the position of an object here we have used uniform distribution and given the coordinates points where our object will range. Similarly rotating is used to rotate the object in different directions to add diversity to our data. For all practical purposes, position and rotation are used to make data more diverse and general, which will affect the accuracy of our perception model positively.
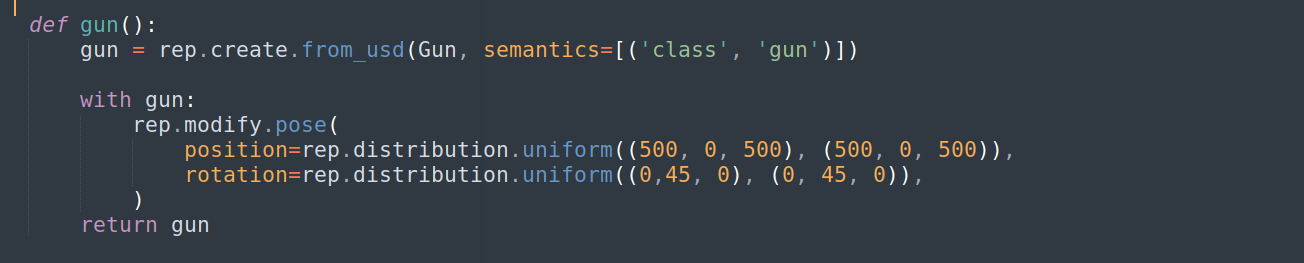
Calling randomizer function from the replicator. This line of code will randomize the object on the given coordinates.

Creating a camera and attaching it to the rendered product ensures that all frames captured will include the target object. This code allows the camera to render along with the target object. Without attaching the camera to the rendering object, some frames may be missing the target object, which would be useless for training the DL model.

Attaching a writer to save annotations in .npy file format. Omniverse replicator provides various annotation patterns; in this case, we used bounding_box_2d_tight.

Generating frames with objects of different sizes from various angles is possible in Omniverse. Generating a large amount of data is straightforward, as you can specify the parameter ‘num_frames’ with integer values such as 10, 1000, or 10000. This will capture the specified number of frames.

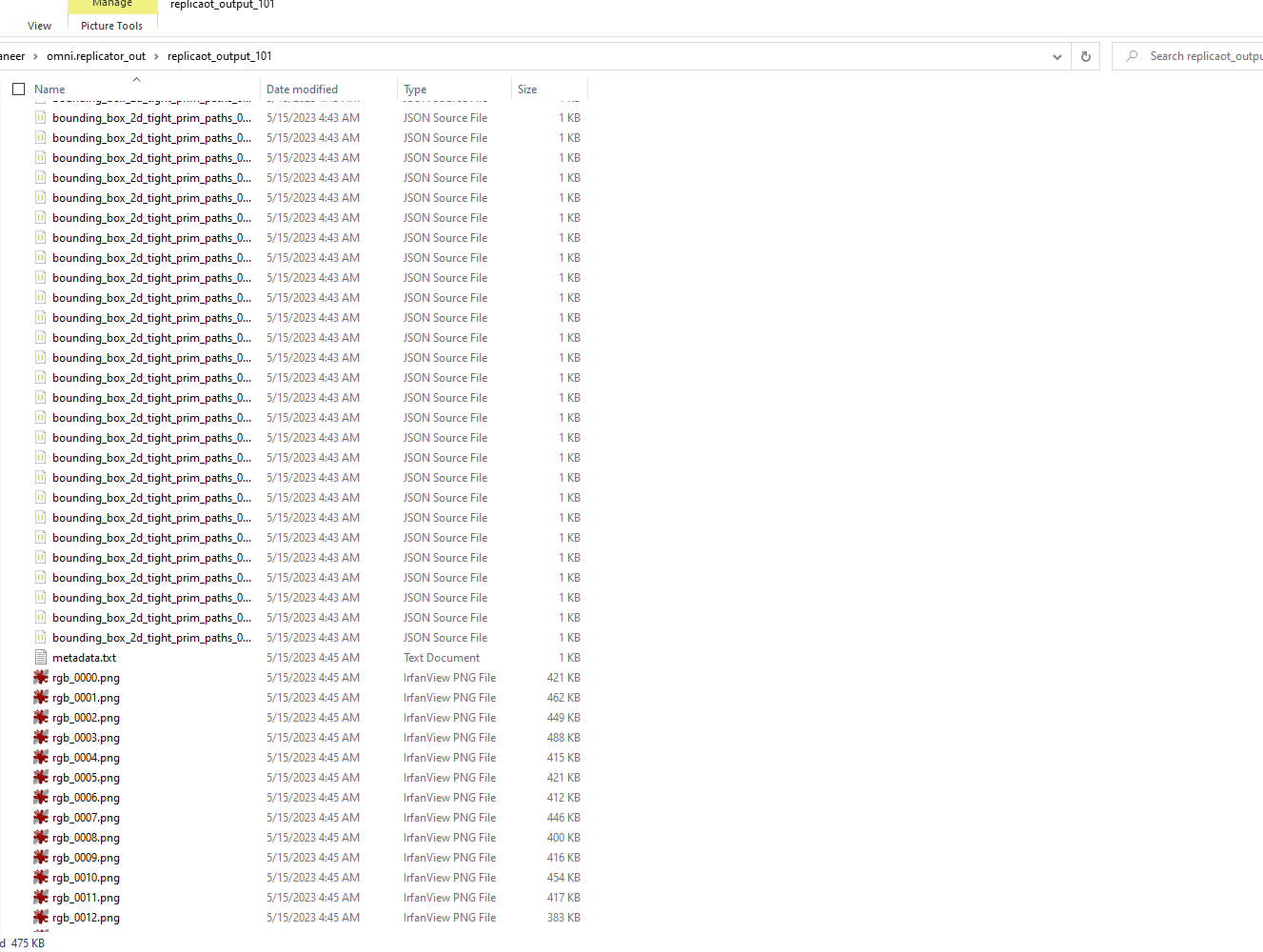
Output directory: The purpose of an output directory is to store and organize the output files generated by a program or process.
Synthetic data generation using replicators is a powerful approach that enables the creation of artificial data that closely resembles real data. Replicators are algorithms or models that learn the underlying patterns and statistical characteristics of the original data and generate synthetic samples based on that knowledge.
The use of replicators for synthetic data generation offers several advantages. Firstly, it allows for the generation of large-scale datasets that can be used for various purposes, such as training machine learning models or conducting data analysis. Replicators can capture the intricate relationships and dependencies present in the original data, resulting in synthetic samples that closely mimic the real data distribution.
Secondly, synthetic data generated using replicators can help address privacy concerns. By removing or obscuring sensitive or personally identifiable information, replicators can create synthetic datasets that preserve privacy while maintaining the statistical properties of the original data. This facilitates data sharing and collaboration while mitigating the risks associated with handling sensitive information.
Additionally, replicators offer flexibility in data generation. They can be trained on specific subsets of data or be guided to focus on features or patterns of interest. This allows for the creation of synthetic data that is tailored to specific use cases or research objectives. Replicators also enable the simulation of rare or extreme events that may be challenging to capture in real data, making them valuable for testing and validating models in scenarios with limited occurrences.
However, it is important to consider certain limitations and challenges associated with synthetic data generation using replicators. The quality and accuracy of the synthetic data heavily rely on the quality and representativeness of the original data used for training the replicator models. Biases or limitations present in the training data can be propagated to the synthetic data, leading to potential issues or inaccuracies.
Additionally, the evaluation and validation of models trained on synthetic data is crucial. Careful validation and testing procedures should be employed to ensure the reliability and applicability of the models in real-world settings.
In conclusion, synthetic data generation using replicators is a valuable approach that offers numerous benefits, including dataset scalability, privacy preservation, and flexibility in data generation. It can be a useful tool in various domains, but careful consideration should be given to the quality of the training data and the validation of models to ensure the reliability and effectiveness of the generated synthetic data.
